28. 文件系统
文件系统
文件 = struct file_operations
- 数据文件:hello.c, a.out, …
- 虚拟的磁盘
- vector
- 设备驱动
- null, nuke0, …
- 虚拟文件
- 进程的地址空间, …
新需求:怎么管理系统中众多的文件?
- find_file_by_name?
管理文件
文件那么多,怎么找到想要的?
- 信息的局部性:将虚拟磁盘 (文件) 组织成层次结构
思路:信息的局部性
树状层次结构
- 逻辑相关的数据存放在相近的目录
1 | . |
麻烦的是 “非数据” 的文件
UNIX/Linux: Everything is a File
- 一切都在 “/” 中 (例子:中文语言包, fstab)
Windows 的设计
- 一个驱动器一棵树:A:, B:, C:, …
- 其他命名空间:Windows Driver Model, Registry
- (也可以 “everything is a file”)
1 | HANDLE hDevice = CreateFile( |
UNIX 的设计:目录树的拼接
mount: 将一个目录解析为另一个文件系统的根
mount(source, target, filesystemtype, mountflags, data);
- 再看 “最小 Linux”
- 初始时只有 /dev/console 和几个文件
- /proc, /sys, 甚至 /tmp 都没有
- 答案:它们都是 mount 系统调用创建出来的
- UNIX 一贯的设计哲学:灵活
- Linux 安装时的 “mount point”
- /, /home, /var 可以是独立的磁盘设备
- Linux 安装时的 “mount point”
Quiz
如何挂载一个 filesystem.img?
- 一个微妙的循环
- 文件 = 磁盘上的虚拟磁盘
- 挂载文件 = 在虚拟磁盘上虚拟出的虚拟磁盘
- 镜像
Linux 的处理方式
创建一个 loopback (回环) 设备
- 设备驱动把设备的 read/write 翻译成文件的 read/write
- drivers/block/loop.c
- 实现了 loop_mq_ops (不是 file_operations)
观察挂载文件的 strace
- lsblk 查看系统中的 block devices (strace)
- strace 观察挂载的流程
- ioctl(3, LOOP_CTL_GET_FREE)
- ioctl(4, LOOP_SET_FD, 3)
Filesystem Hierarchy Standard
我们看到的目录结构
- FHS enables software and user to predict the location of installed files and directories.
- 例子:macOS 是 UNIX 的内核 (BSD), 但不遵循 Linux FHS
文件系统 API: 目录管理
mkdir
- 创建目录
rmdir
- 删除一个空目录
- 没有 “递归删除” 的系统调用
- rm -rf 会遍历目录,逐个删除 (试试 strace)
getdents
- 返回 count 个目录项 (ls, find, tree 都使用这个)
- 更友好的方式:globbing
硬 (hard) 链接
需求:系统中可能有同一个运行库的多个版本
- libc-2.27.so, libc-2.26.so, …
- 还需要一个 “当前版本的 libc”
- 程序需要链接 “libc.so.6”,能否避免文件的一份拷贝?
(硬) 链接:允许一个文件被多个目录引用
- 文件系统实现的特性 (ls -i 查看)
- 不能链接目录、不能跨文件系统
- 删除文件的系统调用称为 “unlink” (refcount–)
软 (symbolic) 链接
软链接:在文件里存储一个 “跳转提示”
- 软链接也是一个文件
- 当引用这个文件时,去找另一个文件
- 另一个文件的绝对/相对路径以文本形式存储在文件里
- 可以跨文件系统、可以链接目录、……
几乎没有任何限制
- 类似 “快捷方式”
- 链接指向的位置不存在也没关系
- (也许下次就存在了)
文件系统:实现
文件系统实现
文件的实现
- 文件 = “虚拟” 磁盘
- API: read, write, ftruncate, …
目录的实现
- 目录 = 文件/目录的集合
- API: mkdir, rmdir, readdir, link, unlink, …
mount 的实现
- 最好由操作系统统一管理 (而不是由具体的文件系统实现)
数据结构
借助 RAM 自由布局目录和文件
- 文件系统就是一个 Abstract DataType (ADT)
1 | class FSObject { |
操作系统
对不起,没有 Random Access Memory
- 我们只有 block device
- 两个 API
bread(int bid, struct block *b);bwrite(int bid, struct block *b);
实现:
- read, write, ftruncate, …
- mkdir, rmdir, readdir, link, unlink, …
- 用 bread/bwrite 模拟 RAM → 严重的读/写放大
- 我们需要更适合磁盘的数据结构
我们的敌人和朋友
敌人:读/写放大
- 被迫读写连续的一块数据
朋友:局部性 + 缓存
- 适当地排布数据,使得临近的数据有 “一同访问” 的倾向
- 数据暂时停留在内存,延迟写回
FAT 和 UNIX 文件系统
让时间回到 1980 年
5.25" 软盘:单面 180 KiB
- 360 个 512B 扇区 (sectors)
- 在这样的设备上实现文件系统,应该选用怎样的数据结构?
需求分析
相当小的文件系统
- 目录中一般只有几个、十几个文件
- 文件以小文件为主 (几个 block 以内)
文件的实现方式
- struct block * 的链表
- 任何复杂的高级数据结构都显得浪费
目录的实现方式
- 目录就是一个普通的文件 (虚拟磁盘;“目录文件”)
- 操作系统会对文件的内容作为目录的解读
- 文件内容就是一个 struct dentry[];
用链表存储数据:两种设计
- 在每个数据块后放置指针
- 优点:实现简单、无须单独开辟存储空间
- 缺点:数据的大小不是 ; 单纯的 lseek 需要读整块数据
- 将指针集中存放在文件系统的某个区域
- 优点:局部性好;lseek 更快
- 缺点:集中存放的数据损坏将导致数据丢失
哪种方式的缺陷是致命、难以解决的?
集中保存所有指针
集中存储的指针容易损坏?存$n $份就行!
- FAT-12/16/32 (FAT entry,即 “next 指针” 的大小)
“File Allocation Table” 文件系统
RTFM 得到必要的细节
- 诸如 tutorial、博客都不可靠
- 还会丢失很多重要的细节
1 | if (CountofClusters < 4085) { |
FAT: 链接存储的文件
“FAT” 的 “next” 数组
- 0: free; 2… MAX: allocated;
- ffffff7: bad cluster; ffffff8-ffffffe, -1: end-of-file
目录树实现:目录文件
以普通文件的方式存储 “目录” 这个数据结构
- FAT: 目录 = 32-byte 定长目录项的集合
- 操作系统在解析时把标记为目录的目录项 “当做” 目录即可
- 可以用连续的若干个目录项存储 “长文件名”
- 思考题:为什么不把元数据 (大小、文件名、……) 保存在
vector<struct block *>file 的头部?
Talk is Cheap, Show Me the Code!
首先,观察 “快速格式化” (mkfs.fat) 是如何工作的
- 老朋友:strace
然后,把整个磁盘镜像 mmap 进内存
- 照抄手册,遍历目录树 (fat-tree demo),试试镜像
另一个有趣的问题:文件系统恢复
- 快速格式化 = FAT 表丢失
- 所有的文件内容 (包括目录文件) 都还在
- 只是在数据结构眼里看起来都是 “free block”
- 猜出文件系统的参数 (SecPerClus, BytsPerSec, …),恢复 next 关系
FAT: 性能与可靠性
性能
+小文件简直太合适了-但大文件的随机访问就不行了- 4 GB 的文件跳到末尾 (4 KB cluster) 有次 next 操作
- 缓存能部分解决这个问题
- 在 FAT 时代,磁盘连续访问性能更佳
- 使用时间久的磁盘会产生碎片 (fragmentation)
- malloc 也会产生碎片,不过对性能影响不太大
可靠性
- 维护若干个 FAT 的副本防止元数据损坏 (额外的开销)
想要一个更好的文件系统?
不能 “尽善尽美”,但可以在 “实际 workload” 下尽可能好
| Summary | Findings |
|---|---|
| Most files are small | Roughly 2K is the most common size |
| Average file size is growing | Almost 200K is the average |
| Most bytes are stored in large files | A few big files use most of the space |
| File systems contains lots of files | Almost 100K on average |
| File systems are roughly half full | Even as disks grow, file systems remain ~50% full |
| Directories are typically small | Many have few entries; most have 20 or fewer |
ext2/UNIX 文件系统
按对象方式集中存储文件/目录元数据
- 增强局部性 (更易于缓存)
- 支持链接
为大小文件区分 fast/slow path
- 小的时候应该用数组
- 连链表遍历都省了
- 大的时候应该用树 (B-Tree; Radix-Tree; …)
- 快速的随机访问
ext2: 磁盘镜像格式
对磁盘进行分组
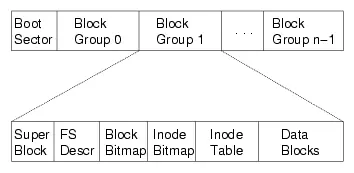
“superblock”:文件系统元数据
- 文件 (inode) 数量
- block group 信息
- ext2.h 里有你需要知道的一切
ext2 目录文件
与 FAT 本质相同:在文件上建立目录的数据结构
- 注意到 inode 统一存储
- 目录文件中存储文件名到 inode 编号的 key-value mapping
ext2: 性能与可靠性
局部性与缓存
- bitmap, inode 都有 “集中存储” 的局部性
- 通过内存缓存减少读/写放大
大文件的随机读写性能提升明显
- 支持链接 (一定程度减少空间浪费)
- inode 在磁盘上连续存储,便于缓存/预取
- 依然有碎片的问题
但可靠性依然是个很大的问题
- 存储 inode 的数据块损坏是很严重的
把文件系统理解成一个 “数据结构”,就不难分析其中的重点和实现要点——我们总是把数据按照局部性组织起来,无论是 FAT 还是 bitmap/inode 的设计,都利用了这一点。另一个重要的设计是 “目录也是文件”——文件系统实现将目录文件中的数据作出解读,从而解析出其中的目录结构。