12. 并发 Bugs
1 致命的并发Bugs
事件级的并发
1 | Event(doMouseMove) { |
Therac-25 Incident (1985-1987)
- 事件驱动导致的并发 bug,导致至少 6 人死亡
Diablo I 案例再现
- 选择 X-Ray (High) Mode
- 机器开始移动 mirror,大约需要 8s 完成…
- 切换到 Electron (Low) Mode (OK)
- 再迅速切换到 X-Ray (High) Mode
- Assertion fail: Malfunction 54; 操作员下意识地按下 Continue……
全数字化带来的悲剧
- 在更早的产品 (Therac-20) 中,assertion fail 会触发电路互锁 (interlock) 直接停机,需要手工重启
问题修复后……
- If the operator sent a command at the exact moment the counter overflowed, the machine would skip setting up some of the beam accessories
最终解决方法
- 独立的硬件安全方案
- 检测到大计量照射时直接停机
思考:AI 时代的 “最后防线” 在哪里?
- 我们会不会从此生活在 AI 为我们生成的幻觉中?
历史上,还有许多并发性导致的严重事故,包括 2003 年美加大停电,估计经济损失 250 亿—300 亿美元。并发 bug 难捉摸的重要原因之一来自它触发的不确定性,即便经历严格的测试,仍有罕见的调度可能导致连锁反应;直到 2010 年左右,学术界和工业界才对并发系统的正确性开始有了系统性的认识。
2 死锁
2.1 死锁产生的必要条件
System deadlocks (1971): 把锁看成袋子里的球
- Mutual-exclusion - 一个口袋一个球,得到球才能继续
- Wait-for - 得到球的人想要更多的球
- No-preemption - 不能抢别人的持有的球
- Circular-chain - 形成循环等待球的关系
“必要条件”?
- 打破任何一个条件,就不会发生死锁了
“理解了死锁的原因,尤其是产生死锁的四个必要条件,就可以最大可能地避免、预防和解除死锁。所以,在系统设计、进程调度等方面注意如何不让这四个必要条件成立,如何确定资源的合理分配算法,避免进程永久占据系统资源。此外,也要防止进程在处于等待状态的情况下占用资源。因此,对资源的分配要给予合理的规划。”
不能称为是一个合理的 argument
- 对于玩具系统/模型
- 我们可以直接证明系统是 deadlock-free 的
- 对于真正的复杂系统
- 哪一个条件最容易打破?
2.2 在实际系统中避免死锁?
Lock ordering
- 任意时刻系统中的锁都是有限的
- 给所有锁编号 (Lock Ordering)
- 严格按照从小到大的顺序获得锁
Proof (sketch)
- 任意时刻,总有一个线程获得 “编号最大” 的锁
- 这个线程总是可以继续运行
3 数据竞争
不同的线程同时访问同一内存,且至少有一个是写。
- 两个内存访问在 “赛跑”,“跑赢” 的操作先执行
- 例子:共享内存上实现的 Peterson 算法
“跑赢” 并没有想象中那么简单
- Weak memory model 允许不同观测者看到不同结果
- Since C11: data race is undefined behavior
3.1 例子
Case 1: 上错了锁
1 | void T_1() { spin_lock(&A); sum++; spin_unlock(&A); } |
Case 2: 忘记上锁
1 | void T_1() { spin_lock(&A); sum++; spin_unlock(&A); } |
不同的线程同时访问同一内存,且至少有一个是写
1 | void wait_next_beat(int expect) { |
- 实际不是忘记上锁,是用错了变量
- 更致命的:bug (error state) 很难触发 “Heisenbugs”
实际系统面临更复杂的情况
- “内存” 可以是地址空间中的任何内存
- 可以是全部变量
- 可以是堆区分配的变量
- 可以是栈
- “访问” 可以是任何代码
- 可能发生在你的代码里
- 可以发生在框架代码里
- 可能是一行你没有读到过的汇编代码
- 可能是一条 ret 指令
4 原子性/顺序违反
4.1 并发编程的本质困难
人类是 sequential creature
- 我们只能用 sequential 的方式来理解并发
- 程序分成若干 “块”,每一块看起来都没被打断 (原子)
- 例子:produce → (happens-before) → consume
- 程序分成若干 “块”,每一块看起来都没被打断 (原子)
并发控制的机制完全是 “后果自负” 的
- 互斥锁 (lock/unlock) 实现原子性
- 忘记上锁——原子性违反 (Atomicity Violation, AV)
- 条件变量/信号量 (wait/signal) 实现先后顺序同步
- 忘记同步——顺序违反 (Order Violation, OV)
97% 的非死锁并发 bug 都是原子性或顺序错误
4.2 原子性违反 (Atomicity Violation)
“ABA”: 代码被别人 “强势插入”
- 即便分别上锁 (消除数据竞争),依然是 AV
- Diablo I 里复制物品的例子
- Therac-25 中 “移动 Mirror + 设置状态”
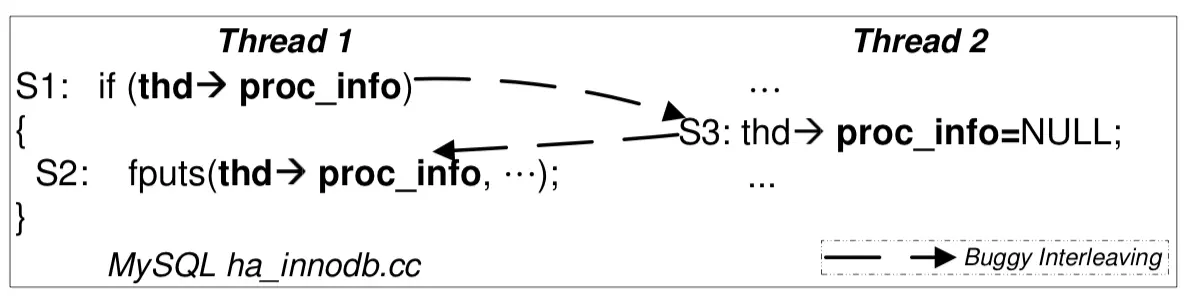
4.3 顺序违反 (Order Violation)
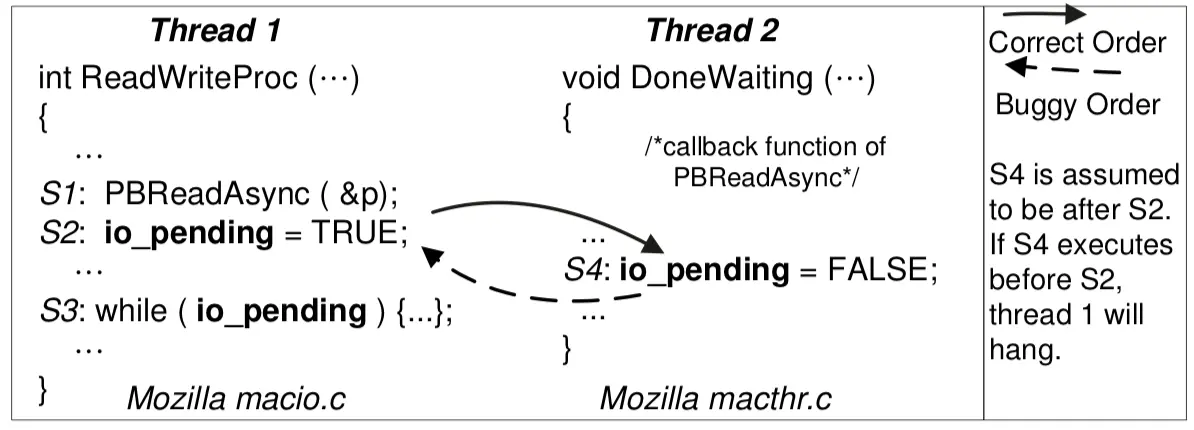
“BA”: 事件未按预定的顺序发生
- 例子:concurrent use-after-free
实际上,“原子性” 一直是并发控制的终极目标。对编程者而言,理想情况是一段代码的执行要么看起来在瞬间全部完成,要么好像完全没有执行过。代码中的副作用:共享内存写入、文件系统写入等,则都是实现原子性的障碍。
因为 “原子性” 如此诱人,在计算机硬件/系统层面提供原子性的尝试一直都没有停止过:从数据库事务 (transactions, tx) 到软件和硬件支持的 Transactional Memory (“an idea ahead its time”) 到 Operating System Transactions,直到今天我们依然没有每个程序员都垂手可得的可靠原子性保障。
而保证程序的执行顺序就更困难了。Managed runtime 实现自动内存管理、channel 实现线程间通信等,都是减少程序员犯错的手段。
人类本质上是 sequential creature,因此总是通过 “块的顺序执行” 这一简化模型去理解并发程序,也相应有了两种类型的并发 bugs:
- Atomicity violation,本应原子完成不被打断的代码被打断
- Order violation,本应按某个顺序完成的未能被正确同步
与这两类 bugs 关联的一个重要问题是数据竞争,即两个线程同时访问同一内存,且至少有一个是写。数据竞争非常危险,因此我们在编程时要尽力避免。